





More Innovation:
What is Containerization? A Quick Tutorial and History



Updated: April 14, 2021
Containerization with Docker and Kubernetes
Containerization is grabbing headlines in the application development and deployment space, but what are they, and why should you care?
In this tutorial, we’ll attempt to answer those questions.
Containers and Docker
To understand what containerization is, we need to jump into a time machine and go back to the 1990s. At that time, organizations built servers on the traditional architecture – a physical box with an operating system installed and one or two monolithic applications running on it. As demand for network-based services increased, datacenters grew in size, but each server typically ran at 50% utilization max. To be blunt, there was a lot of waste here – wasted space, wasted compute capacity and wasted electricity.
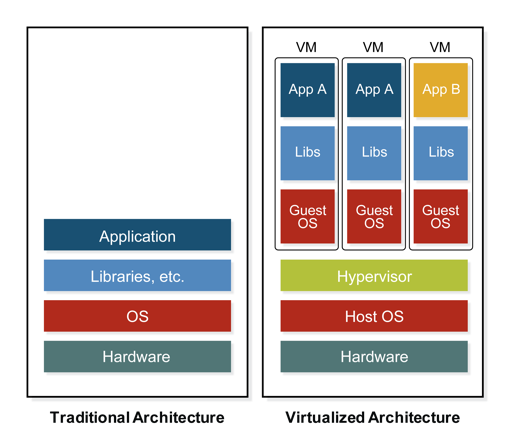
In the early 2000s, virtualization came to the rescue, abstracting compute, storage, and networking from the physical hardware. A single server could host multiple apps, all running in dedicated virtual machines (VMs) with a hypervisor orchestrating them. Servers could run at much higher utilization, and data centers were downsized. Additionally, VMs could be “saved” as image files, making it far easier to port, scale and recover applications.
Warning – rabbit hole
Human beings take the most amazing inventions for granted.
Consider the car, which is truly astonishing. A hundred years ago, cars were barely out of infancy; now, it’s hard to imagine life without them. Along the way, every major step in the car’s evolution has been forgotten.
Do we thank an engineer that we do not have to crank start our cars?
No.
If anything, we wonder why they haven’t been improved more. Where are our autonomous vehicles?
Human beings get bored easily.
Back on track …
In computing, our lack of appreciation for yesterday’s inventions and our appetite for innovation is neatly encapsulated by Moore’s Law (the number of transistors on a chip will double every two years). This hunger for innovation quickly affected virtualization as well, with application developers and system administrators quickly pushing the boundaries. They wanted to scale their infrastructure and build applications even faster. And they noticed some drawbacks with virtualization:
- The hypervisor layer added additional time and processing requirements
- The VMs themselves included unnecessary libraries and OS elements
and
- It took a long time to spin up vast numbers of VMs.
Pushing these boundaries led to some fundamental questions like “Is the hypervisor layer really necessary?” or “How small can a VM get?”
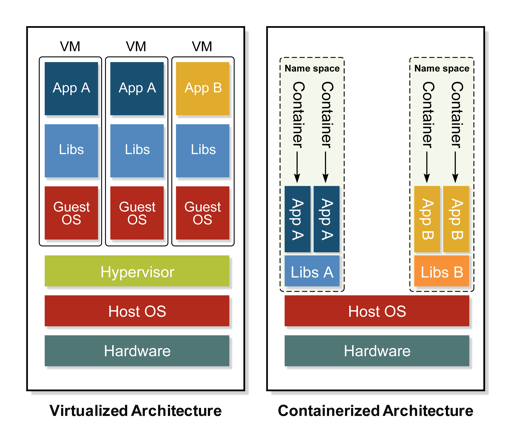
Enter the container, a tiny unit of software that packages an application’s executable code with precisely the libraries it needs so it can run on multiple different computing environments. It was a superb idea that ran into a couple of initial snags:
- The base OS needed a runtime to manage containers
and
- Creating containers proved difficult
The Docker company was the first to solve these problems back in 2013.
Their containerization runtime and creation tools have become extremely popular in the IT industry. Docker Hub provides an online repository for publicly available and privately held container images. – the static files that store all the code and libraries needed for a containerized app to come to life. The Docker command-line interface works well on Linux and provides the tools to create, run, modify and save containers.
VMs vs Containers
This table provides a brief comparison between VMs and Containers:
| Characteristics of VMs | Characteristics of Containers |
| Includes a complete guest OS | Includes only necessary binaries, etc. (typically tiny compared to a VM) |
| Takes minutes to spin up a VM | Takes seconds (or less) to spin up a container |
| Requires a hypervisor | Requires only a container runtime |
| Self-contained; all OS resources available to applications in the VM | Dependent on host OS; limited resources available within the container |
| Resource requests are translated by the hypervisor to the host OS | Resource requests are passed directly to the host OS |
| Strong isolation between VMs | Weak isolation between containers |
To summarize, the initial question around containerization was: “How can I create and run a smaller, faster, next-generation VM?” And the most popular answer has been “Build and use a Docker container.”
Containerization: Orchestration and Kubernetes
After introducing Docker containerization, another question followed right afterwards: “How can I deploy and manage containers at scale?”
(When people said, “at scale,” they meant “AT SCALE!” – hundreds and thousands of containers in production environments worldwide.)
Manually starting new containers thousands of times a day isn’t feasible. Docker has an orchestration tool called Docker Swarm, but the industry-wide love for the Docker runtime did not extend to Swarm.
In another part of the Cloud, Google had been successfully managing massive workloads on a global scale using an internal cluster manager called Borg. In 2014, Google open-sourced Borg’s container orchestration toolset under the name “Kubernetes” (the Greek word for a helmsman on a ship and interestingly related to the English word governor).
From the words of www.kubernetes.io, Kubernetes is an “open-source system for automating deployment, scaling and management of containerized applications.” Kubernetes released v1.0 in mid-2015.
At the same time, Google partnered with the Linux Foundation and donated Kubernetes as a seed technology to form the Cloud Native Computing Foundation (CNCF), the body that maintains Kubernetes. Since that time, the popularity of Kubernetes has exploded, as has the number of related open source projects under the CNCF’s umbrella.
Check out the CNCF’s Interactive Landscape to get a view of all the Cloud Native projects on the go.
Kubernetes Architecture
To understand how Kubernetes works, I’ll talk about three elements and one phrase. The elements are the cluster, the node and the pod. The phrase is “desired cluster state.”
Simplistically speaking, a pod is a container, a node is a VM running multiple pods, a cluster is a collection of nodes under one management and the desired cluster state defines which pods are running on which nodes. Kubernetes continually drives the actual cluster state towards the desired cluster state.
For example, suppose you want to run a website called www.MyKube.com using Nginx as your web server. You’d want at least 100 Nginx pods running at all times, with automatic scaling depending on traffic levels – 50 in your Toronto datacenter and 50 in your Dubai datacenter.
Kubernetes can do this for you (and much more).
To achieve this sort of automated orchestration, Kubernetes uses an intricate, layered architecture that is a little reminiscent of TCP/IP layering. It can be a bit overwhelming at first, but you will appreciate the power in the Kubernetes architecture as you learn more.
So, let’s look deeper at nodes and pods, and also introduce you to Deployments and Services.
Nodes
For starters, there are two types of nodes: a master node, that provides the orchestration; and a worker node, that runs the pods. For MyKube.com, you’ll want a couple of master nodes and multiple worker nodes to provide node-level redundancy. And let me emphasize that the master has all the intelligence; the workers just run the pods.
Pods
More abstract than a container, a pod runs one container or multiple tightly coupled containers that always work together. This is especially useful for applications built on a micro-service architecture (more on that in a future blog). Another critical point is that pods are designed to be mortal. Don’t count on any particular MyKube Nginx pod to still be around next week.
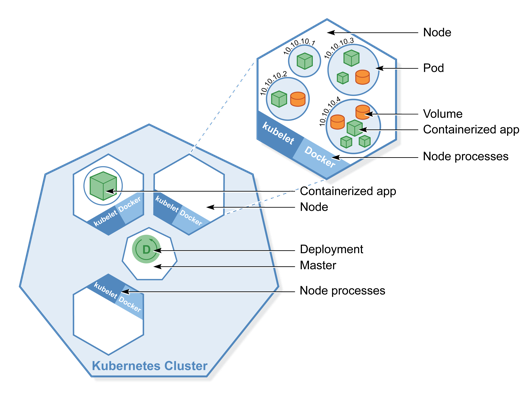
Deployments
A Deployment is the Kubernetes object that enables you to keep a specified number of pods up and running. In our MyKube.com example, you’d create a Deployment to run 50 Nginx pods in Toronto and another Deployment to run 50 Nginx pods in Dubai. If one Toronto pod goes down, another will take its place.
That statement hides a vital detail – the worker node with the bad pod doesn’t just spin up a new one directly. It informs the master node first. The master checks on the desired state and then re-aligns the current state with that desired state. If the best approach is to spin up a new pod on the same node, it will be done. If some conditions have changed or the desired state has been redefined (more pods in Dubai, fewer in Toronto), the master can spin up the new pod in the best location. Keeping all the intelligence and decision-making with the master enables this sort of enhanced control.
Services
Here’s a fun fact – every pod receives a dynamically assigned IP address when it’s created. While each node in the cluster has a unique pool of IPs, our MyKube Deployment spans multiple worker nodes which would make accessing the website by directly hitting an Nginx pod nearly impossible.
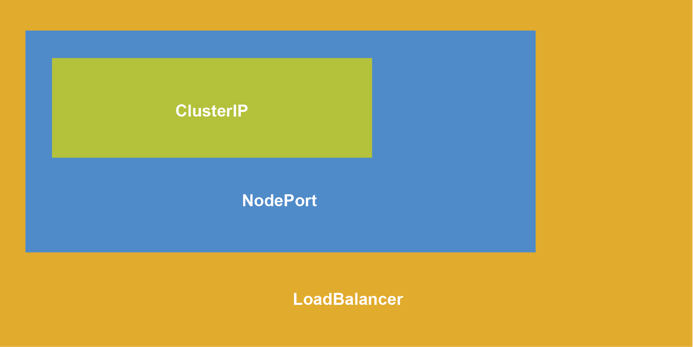
Fortunately, Kubernetes has a solution for that as well, called a Service. A Service is the Kubernetes object that provides a high-level abstraction for networking within the cluster and beyond. There are multiple types of Services, all related in a layered architecture.
Cluster IP
A ClusterIP Service works at the cluster level and assigns an IP: port pair that gets mapped to a specific pod or pods. For example, we could create a ClusterIP Service called MyKube-CIP with an IP and port of 10.150.150.1:80 that sends requests to port 80 on one of our Nginx pods. This is very useful for other pods in the cluster, but it doesn’t help a user.
nodePort
A nodePort Service works on the LAN level. The service assigns a port on the node that maps to an associated ClusterIP Service. For example, we could create a nodePort Service called MyKube-NP that uses port 31235 on your node. Any requests coming to <nodeIP>:31235 are sent to MyKube-CIP and then to one of our Nginx pods. This is useful for users on the LAN, but it still doesn’t help customers get to our MyKube.com website.
LoadBalancer
The last piece of this puzzle is the LoadBalancer Service.
The LoadBalancer works with a cloud provider’s infrastructure to expose our MyKube.com website to the world. On the backside, it maps to a nodePort Service that then maps to a ClusterIP Service and finally to one of our Nginx pods.
The beauty here is that you can define whichever sort of Service you need – no more, no less.
Summary
In conclusion, containerization needs Docker and Kubernetes to work together. Docker enables you to create containerized applications, run them on each node, and store images on Docker Hub. Kubernetes provides orchestration for containers at scale, allowing you to quickly deploy and manage thousands of pods, with automated health checks and layered networking.
Trying to understand the fundamentals of containerization with Docker and Kubernetes? Build your expertise with CENGN Academy’s Docker and Kubernetes Basics Course in partnership with UOttawa’s Professional Development Institute!
About the Author

Peter Heath is CENGN’s Senior Manager for Training Programs, driving CENGN Academy’s strategic focus and leading the training development/delivery team. Throughout his career, Peter has developed expertise in multiple telecom, networking and information technology specializations. Before joining CENGN, Peter had broad experience in teaching, training, and program development across the higher education and commercial education sectors. Peter holds a Ph.D. in Mathematics from Carleton University in Canada and has achieved multiple networking and IT industry certifications.
More by Peter Heath